RX 6800 XT 内核魔改教程:五年老卡 MoE 速度暴增至 1770t/s
2026-05-13 14:26:56
5 月 13 日消息,开发者 Stormrage34 近日发布 llama.cpp 分支「TurboQuant-HIP v0.3.0」版本;通过重写矩阵乘法内核,成功将 AMD RX 6800 XT 显卡的 MoE 大模型预填充速度——从上游 llama.cpp 主分支下的约 480 t/s——提升至 1770 t/s。
该团队长期维护面向AMD GPU深度适配的llama.cpp专属分支,专门针对AMD硬件特性优化大语言模型推理性能。

上游官方版本llama.cpp此前将AMD GPU作为通用后端适配,核心计算内核均针对NVIDIA架构开发,随后直接移植到AMD后端,在RDNA2架构上存在大量带宽浪费问题,MoE场景运算完全受内存带宽限制。
该团队从HIP底层切入做针对性改进,新开发的基于BFE的IQ4_XS反量化内核,独立运行速度较原有方案提升13倍。
同时,新增异步流水线调度逻辑,将内核启动延迟和运算过程做重叠处理,直接降低31%的内核启动开销。
带来MoE场景约4倍性能跃升的核心,是实验性LDS双缓冲矩阵乘法内核,实现权重加载和DP4A计算并行,最大化利用硬件算力资源。
目前该核心优化功能仅开放手动标志位启用,仍存在对称瓦片尺寸下的LDS存储体冲突问题,导致延迟波动偏高暂不适合生产环境,完整修复方案已经制定完成。
用户可通过项目仓库提供的脚本直接构建测试版本,无需修改CMake配置文件,该分支完整保留上游全部原有功能。

声明:文章不代表链懂观点及立场,不构成本平台任何投资建议。投资决策需建立在独立思考之上,本文内容仅供参考,风险自担!转载请注明出处!侵权必究!
 相关阅读
相关阅读
-
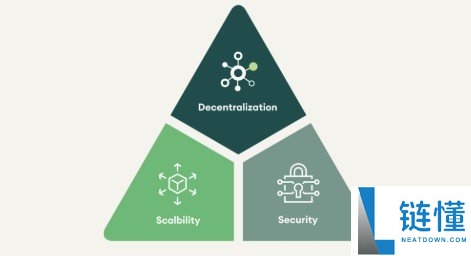
区块链三难困境详解:破解去中心化、安全性与可扩展性的不可能三角链知识 2026-05-13 14:24:22
-
探秘919影院永久免费版:一款颠覆传统观影体验的直播视频软件链资讯 2026-05-13 14:21:00

-
退钱哥自嘲花 2.5 万买美加墨世界杯山顶票:成第一大冤种链资讯 2026-05-13 14:20:50
-
探索三方钱包下载链接.专用直达.top:用户体验与安全性的完美结合链百科 2026-05-13 14:18:46

-
女子请假陪护病危父亲被拒,父去世当天遭开除!法院判决结果出炉链资讯 2026-05-13 14:14:17

-
Revolut 退出欧盟 30 国金银业务,全面加码加密货币投资链知识 2026-05-13 14:08:45

-
剑指纽北!鸿蒙智行智界 FUV 高清谍照:半隐藏门把手 + 大尾翼设计曝光链资讯 2026-05-13 14:08:11

-
探索17c影院天堂免费入口:新时代的直播视频软件选择链资讯 2026-05-13 14:04:19

-
探讨“三方钱包下载链接安全吗”的问题及解决方案链百科 2026-05-13 14:04:13

-
299 元众筹!小米米家长柄筋膜枪 3:自带弯头手柄,轻松按摩后背链资讯 2026-05-13 14:01:28






