国产第一!阿里 Qwen3.7-Max 旗舰模型发布:全自主完成 35 小时复杂任务
2026-05-20 13:59:19
5 月 20 日消息:阿里巴巴在"2026 阿里云峰会”上,正式发布了全新一代千问旗舰模型——Qwen3.7-Max。
在三方机构Arena全球大模型盲测总榜中,Qwen3.7-Max超过Kimi-K2.6、DeepSeek-v4-pro、GLM-5.1,与GPT、Claude、Gemini最强模型接近,位列国产模型第一。
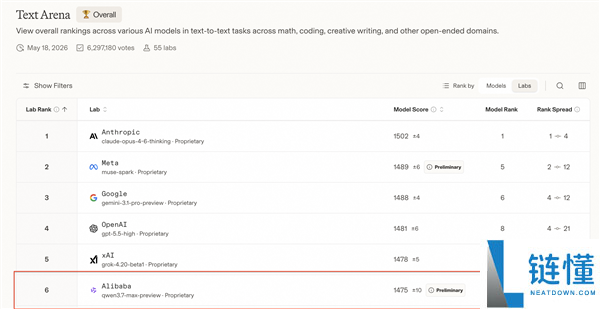
这是千问旗舰模型近三个月内的第三次重大迭代,从3.5到3.6再到3.7,阿里大模型研发节奏明显加速。
Qwen3.7-Max面向智能体(Agent)场景全新设计,在多个核心维度实现突破。
编程方面,在SWE-Pro、SWE-Multilingual等编程智能体测评中均取得领先,Terminal Bench 2.0-Terminus得分69.7,超过DeepSeek-v4-pro-Max和Claude-Opus4.6等。
通用智能体方面,Qwen3.7-Max在MCP-Atlas、MCP-Mark、Skillbench等现实能力测试中表现优异,超越GLM5.1、Kimi-K2.6等模型,创下国产新高。
推理方面,在GPQA Diamond、HLE、HMMT 2026 Feb等推理核心测评中超越Claude-Opus4.6及所有国产模型。
通用能力上,Qwen3.7-Max在指令遵循IFBench评测中得分79.1分创下新高,多语言评测WMT24++、MAXIFE中同样领先。
实战任务测试中,在一个模型训练时从未接触过的全新硬件平台平头哥真武M890芯片上,Qwen3.7-Max在没有任何性能分析数据、硬件文档或新架构的示例内核情况下,从空白工作空间出发,自主完成了推理内核优化任务。
整个过程持续35小时,模型独立进行了432次内核评估和1158次工具调用,完全自主地完成了编写、编译、性能分析与迭代改进的全流程。
最终优化后的推理内核较SGLang Triton官方参考实现取得了10倍加速。
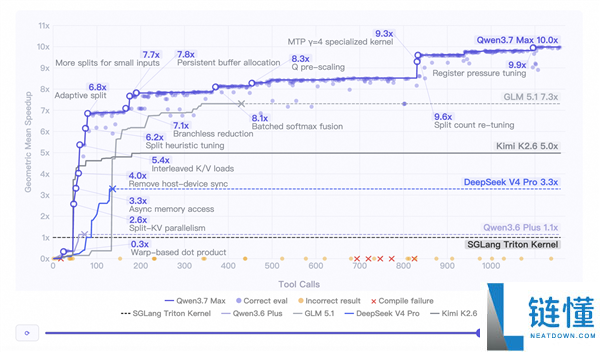
测试轨迹显示,模型在独立运行超过30小时后仍能发现有效优化点,甚至主动发起了一次关键的架构重设计。
在Agent能力方面,Qwen3.7-Max展现出跨框架泛化能力,在Claude Code、OpenClaw、Qwen Code等框架下均能稳定发挥。
通过MCP集成和多智能体协作,该模型在办公自动化基准SpreadSheetBench-v1上斩获87分,处于顶尖水平。
阿里云表示,Qwen3.7-Max API即将上线百炼平台,后续还将推出Qwen3.7-Plus等版本,覆盖从编程智能体到视觉智能体的全场景需求。
 相关阅读
相关阅读
-
哈尔滨双层巴士被高架桥削顶事故通报:官方确认系司机疏忽所致链资讯 2026-05-20 13:53:18

-
中本聪是个人还是组织?深度解析其真实身份与对比特币的颠覆性贡献链知识 2026-05-20 13:51:10

-
Meta 大重组:裁员与转岗并行,7000 人加入 AI 新团队链资讯 2026-05-20 13:47:37

-
推荐:B站必看的30部番,给你带来不一样的观看体验链资讯 2026-05-20 13:46:57

-
阿里平头哥真武 M890 发布:144GB 显存加持,性能三倍碾压英伟达 H20链资讯 2026-05-20 13:41:31

-
捡芝麻丢西瓜!男子喝 4 两酒为省 5 元停车费赶走代驾,涉嫌危险驾驶被刑拘链资讯 2026-05-20 13:36:01

-
A16z 筹集 150 亿美元:加密货币成美国赢得未来百年关键链知识 2026-05-20 13:32:49

-
探索B站国产高清视频的魅力:一款颠覆传统直播视频软件的全新体验链资讯 2026-05-20 13:30:20

-
卖一辆亏一辆!4S 店大崩盘:日均关店 12 家,传统汽车销售渠道彻底凉了?链资讯 2026-05-20 13:30:09

-
微星 Claw 8 EX AI+ 曝光:Intel 锐炫 G3 掌机配 32GB 内存与 80Wh 大电池链资讯 2026-05-20 13:24:21








